文本摘要
本教程演示了使用内置链和 LangGraph 进行文本摘要。
该页面的 先前版本 展示了遗留链 StuffDocumentsChain、MapReduceDocumentsChain 和 RefineDocumentsChain。有关使用这些抽象的更多信息以及与本教程中演示的方法的比较,请参见 这里。
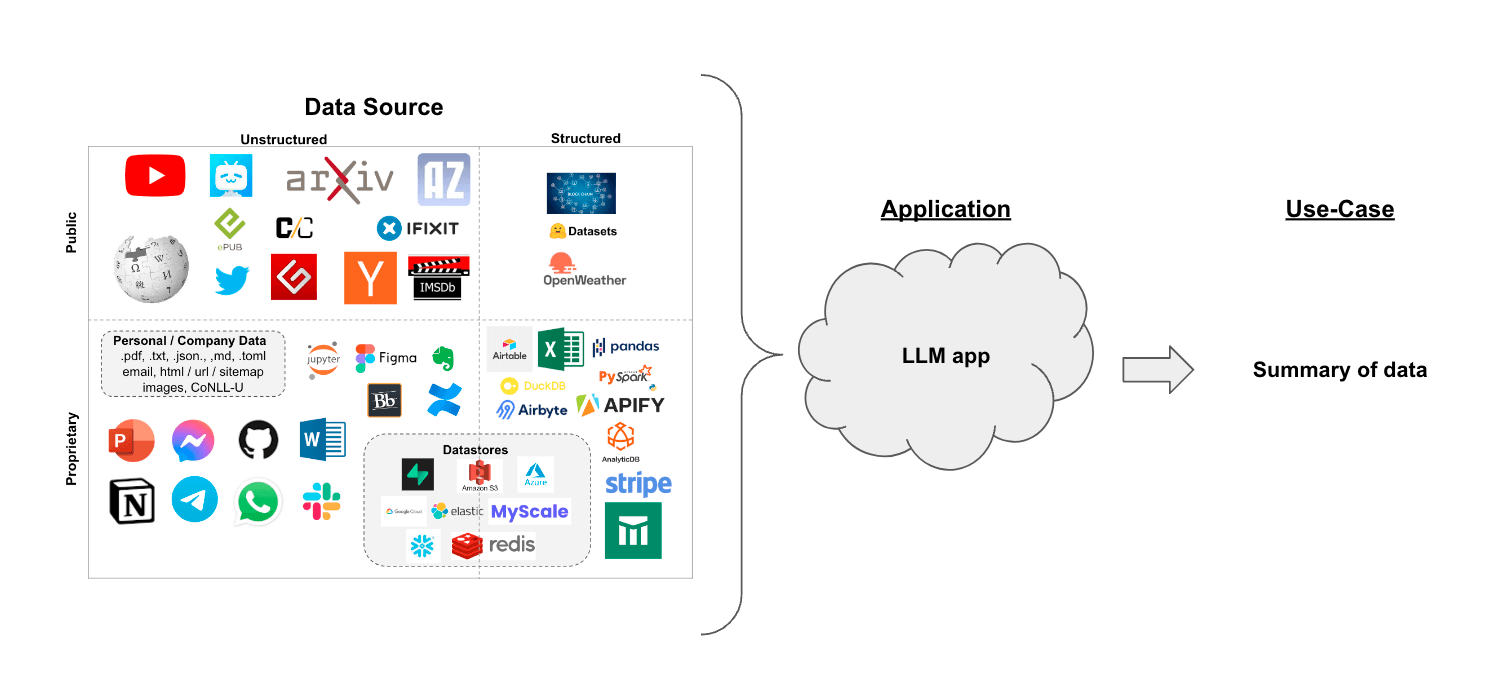
假设您有一组文档(PDF、Notion 页面、客户问题等),您想要总结内容。
大型语言模型(LLMs)在理解和综合文本方面非常出色,因此是一个很好的工具。
在 检索增强生成 的背景下,文本摘要可以帮助提炼大量检索文档中的信息,以为 LLM 提供上下文。
在本教程中,我们将介绍如何使用 LLM 从多个文档中总结内容。
概念
�我们将涵盖的概念有:
-
使用 语言模型。
-
使用 文档加载器,特别是 WebBaseLoader 从 HTML 网页加载内容。
-
有两种方法可以总结或以其他方式组合文档。
- Stuff,它简单地将文档连接成一个提示;
- Map-reduce,适用于较大的文档集。这将文档分成批次,总结这些文档,然后总结这些摘要。
关于这些策略和其他策略的更短、更有针对性的指南,包括 迭代优化,可以在 使用手册 中找到。
设置
Jupyter Notebook
本指南(以及文档中的大多数其他指南)使用 Jupyter notebooks 并假设读者也是如此。Jupyter notebooks 非常适合学习如何使用 LLM 系统,因为有时事情可能会出错(意外输出、API 故障等),在交互环境中逐步阅读指南是更好地理解它们的好方法。
本教程和其他教程可能最方便地在 Jupyter notebook 中运行。有关如何安装的说明,请参见 这里。
安装
要安装 LangChain,请运行:
- Pip
- Conda
pip install langchain
conda install langchain -c conda-forge
有关更多详细信息,请参阅我们的 安装指南。
LangSmith
您使用 LangChain 构建的许多应用程序将包含多个步骤和多次调用大型语言模型。 随着这些应用程序变得越来越复杂,能够检查您的链或代理内部到底发生了什么变得至关重要。 做到这一点的最佳方法是使用 LangSmith。
在您注册上述链接后,请确保设置您的环境变量以开始记录跟踪:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
或者,如果在笔记本中,您可以使用以下方式设置:
import getpass
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
概述
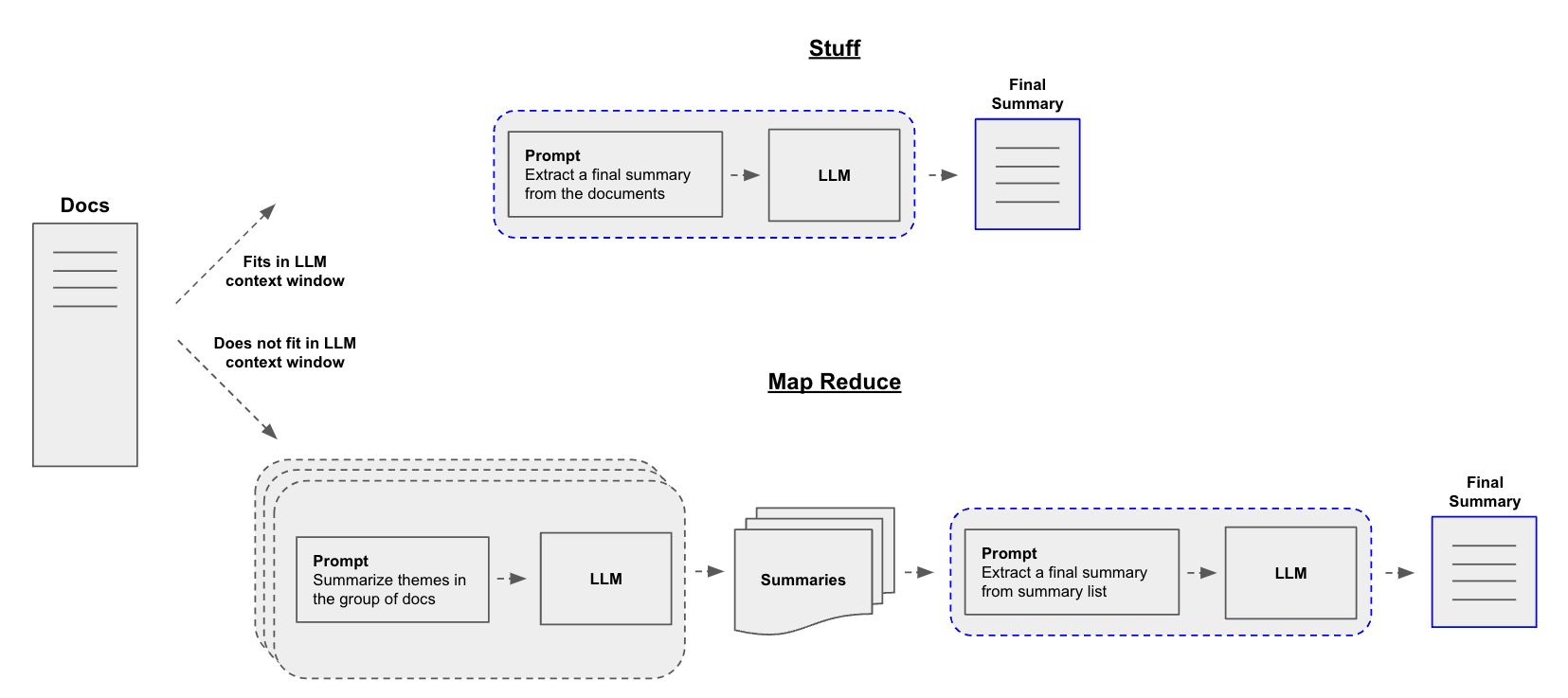
构建摘要生成器的一个核心问题是如何将您的文档传递到大型语言模型的上下文窗口中。常见的两种方法是:
-
Stuff:简单�地将所有文档“填充”到一个提示中。这是最简单的方法(有关create_stuff_documents_chain构造函数的更多信息,请参见 这里,该方法用于此方法)。 -
Map-reduce:在“映射”步骤中单独总结每个文档,然后将摘要“归约”成最终摘要(有关MapReduceDocumentsChain的更多信息,请参见 这里,该方法用于此方法)。
请注意,当对子文档的理解不依赖于前面的上下文时,map-reduce 特别有效。例如,在总结许多较短文档的语料库时。在其他情况下,例如总结具有固有顺序的小说或文本,迭代细化 可能更有效。
设置
首先设置环境变量并安装软件包:
%pip install --upgrade --quiet tiktoken langchain langgraph beautifulsoup4
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
首先我们加载文档。我们将使用 WebBaseLoader 来加载一篇博客文章:
<!--IMPORTS:[{"imported": "WebBaseLoader", "source": "langchain_community.document_loaders", "docs": "https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.web_base.WebBaseLoader.html", "title": "Summarize Text"}]-->
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
接下来让我们选择一个大型语言模型:
- OpenAI
- Anthropic
- Azure
- Cohere
- NVIDIA
- FireworksAI
- Groq
- MistralAI
- TogetherAI
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
pip install -qU langchain-anthropic
import getpass
import os
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-5-sonnet-20240620")
pip install -qU langchain-openai
import getpass
import os
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
import getpass
import os
os.environ["GOOGLE_API_KEY"] = getpass.getpass()
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model="gemini-1.5-flash")
pip install -qU langchain-cohere
import getpass
import os
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import ChatCohere
llm = ChatCohere(model="command-r-plus")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
import os
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain import ChatNVIDIA
llm = ChatNVIDIA(model="meta/llama3-70b-instruct")
pip install -qU langchain-fireworks
import getpass
import os
os.environ["FIREWORKS_API_KEY"] = getpass.getpass()
from langchain_fireworks import ChatFireworks
llm = ChatFireworks(model="accounts/fireworks/models/llama-v3p1-70b-instruct")
pip install -qU langchain-groq
import getpass
import os
os.environ["GROQ_API_KEY"] = getpass.getpass()
from langchain_groq import ChatGroq
llm = ChatGroq(model="llama3-8b-8192")
pip install -qU langchain-mistralai
import getpass
import os
os.environ["MISTRAL_API_KEY"] = getpass.getpass()
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest")
pip install -qU langchain-openai
import getpass
import os
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.together.xyz/v1",
api_key=os.environ["TOGETHER_API_KEY"],
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
)
内容:在单个大型语言模型调用中总结
我们可以使用 create_stuff_documents_chain,特别是如果使用更大的上下文窗口模型,例如:
- 128k 令牌的 OpenAI
gpt-4o - 200k 令牌的 Anthropic
claude-3-5-sonnet-20240620
该链将接受文档列表,将它们全部插入提示中,并将该提示传递给大型语言模型:
<!--IMPORTS:[{"imported": "create_stuff_documents_chain", "source": "langchain.chains.combine_documents", "docs": "https://python.langchain.com/api_reference/langchain/chains/langchain.chains.combine_documents.stuff.create_stuff_documents_chain.html", "title": "Summarize Text"}, {"imported": "LLMChain", "source": "langchain.chains.llm", "docs": "https://python.langchain.com/api_reference/langchain/chains/langchain.chains.llm.LLMChain.html", "title": "Summarize Text"}, {"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "Summarize Text"}]-->
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
# Define prompt
prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\\n\\n{context}")]
)
# Instantiate chain
chain = create_stuff_documents_chain(llm, prompt)
# Invoke chain
result = chain.invoke({"context": docs})
print(result)
The article "LLM Powered Autonomous Agents" by Lilian Weng discusses the development and capabilities of autonomous agents powered by large language models (LLMs). It outlines a system architecture that includes three main components: planning, memory, and tool use.
1. **Planning**: Agents decompose complex tasks into manageable subgoals and engage in self-reflection to improve their performance over time. Techniques like Chain of Thought (CoT) and Tree of Thoughts (ToT) are highlighted for enhancing reasoning and planning.
2. **Memory**: The article distinguishes between short-term and long-term memory, explaining how agents can utilize in-context learning and external vector stores for information retrieval. Maximum Inner Product Search (MIPS) algorithms are discussed for efficient memory access.
3. **Tool Use**: The integration of external tools allows agents to extend their capabilities beyond their inherent knowledge. Examples include MRKL systems and frameworks like HuggingGPT, which facilitate task planning and execution through API calls.
The article also addresses challenges faced by LLM-powered agents, such as finite context length, difficulties in long-term planning, and the reliability of natural language interfaces. It concludes with case studies demonstrating the practical applications of these agents in scientific discovery and interactive simulations.
Overall, the article emphasizes the potential of LLMs as general problem solvers and their ability to function as autonomous agents in various domains.
流式处理
请注意,我们还可以逐个令牌地流式传输结果:
for token in chain.stream({"context": docs}):
print(token, end="|")
|The| article| "|LL|M| Powered| Autonomous| Agents|"| by| Lil|ian| W|eng| discusses| the| development| and| capabilities| of| autonomous| agents| powered| by| large| language| models| (|LL|Ms|).| It| outlines| a| system| overview| that| includes| three| main| components|:| planning|,| memory|,| and| tool| use|.|
|1|.| **|Planning|**| involves| task| decomposition|,| where| agents| break| down| complex| tasks| into| manageable| sub|go|als|,| and| self|-ref|lection|,| allowing| agents| to| learn| from| past| actions| to| improve| future| performance|.
|2|.| **|Memory|**| is| categorized| into| short|-term| and| long|-term| memory|,| with| techniques| like| Maximum| Inner| Product| Search| (|M|IPS|)| used| for| efficient| information| retrieval|.
|3|.| **|Tool| Use|**| highlights| the| integration| of| external| APIs| to| enhance| the| agent|'s| capabilities|,| illustrated| through| case| studies| like| Chem|Crow| for| scientific| discovery| and| Gener|ative| Agents| for| sim|ulating| human| behavior|.
|The| article| also| addresses| challenges| such| as| finite| context| length|,| difficulties| in| long|-term| planning|,| and| the| reliability| of| natural| language| interfaces|.| It| concludes| with| references| to| various| studies| and| projects| that| contribute| to| the| field| of| L|LM|-powered| agents|.||
深入了解
- 您可以轻松自定义提示。
- 您可以通过
llm参数轻松尝试不同的大型语言模型(例如,Claude)。
Map-Reduce: 通过并行化总结长文本
让我们来解析一下map-reduce方法。为此,我们将首先使用大型语言模型(LLM)将每个文档映射到一个单独的摘要。然后,我们将这些摘要减少或合并为一个单一的全局摘要。
请注意,map步骤通常是在输入文档上并行化的。
LangGraph,基于langchain-core构建,支持map-reduce工作流,非常适合这个问题:
- LangGraph允许单个步骤(例如连续摘要)进行流式处理,从而提供更大的执行控制;
- LangGraph的检查点支持错误恢复,扩展人机协作工作流,并更容易融入对话应用程序。
- LangGraph的实现易于修改和扩展,正如我们下面将看到的。
Map
让我们首先定义与map步骤相关的提示,并通过链将其与LLM关联。我们可以使用与上面stuff方法相同的摘要提示:
<!--IMPORTS:[{"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "Summarize Text"}, {"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "Summarize Text"}]-->
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
map_prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\\n\\n{context}")]
)
map_chain = map_prompt | llm | StrOutputParser()
我们还可以使用提示中心来存储和获取提示。
这将与您的 LangSmith API 密钥 一起使用。
例如,请参见地图提示 这里。
from langchain import hub
map_prompt = hub.pull("rlm/map-prompt")
减少
我们还定义了一个链,它将文档映射结果减少为单个输出。
# Also available via the hub: `hub.pull("rlm/reduce-prompt")`
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""
reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
reduce_chain = reduce_prompt | llm | StrOutputParser()
通过 LangGraph 进行 orchestration
下面我们实现一个简单的应用程序,它在文档列表上映射摘要步骤,然后使用上述提示进行减少。
当文本相对于大型语言模型的上下文窗口较长时,Map-reduce 流特别有用。对于长文本,我们需要一种机制,以确保在减少步骤中要总结的上下文不超过模型的上下文窗口大小。在这里,我们实现了摘要的递归“折叠”:输入根据令牌限制进行分区,并生成分区的摘要。此步骤重复进行,直到摘要的总长度在所需限制内,从而允许对任意长度文本进行摘要。
首先,我们将博客文章分块为较小的“子文档”以进行映射:
<!--IMPORTS:[{"imported": "CharacterTextSplitter", "source": "langchain_text_splitters", "docs": "https://python.langchain.com/api_reference/text_splitters/character/langchain_text_splitters.character.CharacterTextSplitter.html", "title": "Summarize Text"}]-->
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
print(f"Generated {len(split_docs)} documents.")
Created a chunk of size 1003, which is longer than the specified 1000
``````output
Generated 14 documents.
接下来,我们定义我们的图。请注意,我们定义了一个人为较低的最大令牌长度为 1,000 个令牌,以说明“折叠”步骤。
<!--IMPORTS:[{"imported": "acollapse_docs", "source": "langchain.chains.combine_documents.reduce", "docs": "https://python.langchain.com/api_reference/langchain/chains/langchain.chains.combine_documents.reduce.acollapse_docs.html", "title": "Summarize Text"}, {"imported": "split_list_of_docs", "source": "langchain.chains.combine_documents.reduce", "docs": "https://python.langchain.com/api_reference/langchain/chains/langchain.chains.combine_documents.reduce.split_list_of_docs.html", "title": "Summarize Text"}, {"imported": "Document", "source": "langchain_core.documents", "docs": "https://python.langchain.com/api_reference/core/documents/langchain_core.documents.base.Document.html", "title": "Summarize Text"}]-->
import operator
from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import (
acollapse_docs,
split_list_of_docs,
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraph
token_max = 1000
def length_function(documents: List[Document]) -> int:
"""Get number of tokens for input contents."""
return sum(llm.get_num_tokens(doc.page_content) for doc in documents)
# This will be the overall state of the main graph.
# It will contain the input document contents, corresponding
# summaries, and a final summary.
class OverallState(TypedDict):
# Notice here we use the operator.add
# This is because we want combine all the summaries we generate
# from individual nodes back into one list - this is essentially
# the "reduce" part
contents: List[str]
summaries: Annotated[list, operator.add]
collapsed_summaries: List[Document]
final_summary: str
# This will be the state of the node that we will "map" all
# documents to in order to generate summaries
class SummaryState(TypedDict):
content: str
# Here we generate a summary, given a document
async def generate_summary(state: SummaryState):
response = await map_chain.ainvoke(state["content"])
return {"summaries": [response]}
# Here we define the logic to map out over the documents
# We will use this an edge in the graph
def map_summaries(state: OverallState):
# We will return a list of `Send` objects
# Each `Send` object consists of the name of a node in the graph
# as well as the state to send to that node
return [
Send("generate_summary", {"content": content}) for content in state["contents"]
]
def collect_summaries(state: OverallState):
return {
"collapsed_summaries": [Document(summary) for summary in state["summaries"]]
}
# Add node to collapse summaries
async def collapse_summaries(state: OverallState):
doc_lists = split_list_of_docs(
state["collapsed_summaries"], length_function, token_max
)
results = []
for doc_list in doc_lists:
results.append(await acollapse_docs(doc_list, reduce_chain.ainvoke))
return {"collapsed_summaries": results}
# This represents a conditional edge in the graph that determines
# if we should collapse the summaries or not
def should_collapse(
state: OverallState,
) -> Literal["collapse_summaries", "generate_final_summary"]:
num_tokens = length_function(state["collapsed_summaries"])
if num_tokens > token_max:
return "collapse_summaries"
else:
return "generate_final_summary"
# Here we will generate the final summary
async def generate_final_summary(state: OverallState):
response = await reduce_chain.ainvoke(state["collapsed_summaries"])
return {"final_summary": response}
# Construct the graph
# Nodes:
graph = StateGraph(OverallState)
graph.add_node("generate_summary", generate_summary) # same as before
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)
# Edges:
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
graph.add_edge("generate_final_summary", END)
app = graph.compile()
LangGraph 允许绘制图结构,以帮助可视化其功能:
from IPython.display import Image
Image(app.get_graph().draw_mermaid_png())

在运行应用程序时,我们可以流式传输图形以观察其步骤序列。下面,我们将简单地打印出步骤的名称。
请注意,由于图中存在循环,指定执行时的 recursion_limit 可能会很有帮助。当超过指定限制时,这将引发特定错误。
async for step in app.astream(
{"contents": [doc.page_content for doc in split_docs]},
{"recursion_limit": 10},
):
print(list(step.keys()))
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['collect_summaries']
['collapse_summaries']
['collapse_summaries']
['generate_final_summary']
print(step)
{'generate_final_summary': {'final_summary': 'The consolidated summary of the main themes from the provided documents is as follows:\n\n1. **Integration of Large Language Models (LLMs) in Autonomous Agents**: The documents explore the evolving role of LLMs in autonomous systems, emphasizing their enhanced reasoning and acting capabilities through methodologies that incorporate structured planning, memory systems, and tool use.\n\n2. **Core Components of Autonomous Agents**:\n - **Planning**: Techniques like task decomposition (e.g., Chain of Thought) and external classical planners are utilized to facilitate long-term planning by breaking down complex tasks.\n - **Memory**: The memory system is divided into short-term (in-context learning) and long-term memory, with parallels drawn between human memory and machine learning to improve agent performance.\n - **Tool Use**: Agents utilize external APIs and algorithms to enhance problem-solving abilities, exemplified by frameworks like HuggingGPT that manage task workflows.\n\n3. **Neuro-Symbolic Architectures**: The integration of MRKL (Modular Reasoning, Knowledge, and Language) systems combines neural and symbolic expert modules with LLMs, addressing challenges in tasks such as verbal math problem-solving.\n\n4. **Specialized Applications**: Case studies, such as ChemCrow and projects in anticancer drug discovery, demonstrate the advantages of LLMs augmented with expert tools in specialized domains.\n\n5. **Challenges and Limitations**: The documents highlight challenges such as hallucination in model outputs and the finite context length of LLMs, which affects their ability to incorporate historical information and perform self-reflection. Techniques like Chain of Hindsight and Algorithm Distillation are discussed to enhance model performance through iterative learning.\n\n6. **Structured Software Development**: A systematic approach to creating Python software projects is emphasized, focusing on defining core components, managing dependencies, and adhering to best practices for documentation.\n\nOverall, the integration of structured planning, memory systems, and advanced tool use aims to enhance the capabilities of LLM-powered autonomous agents while addressing the challenges and limitations these technologies face in real-world applications.'}}
在相应的 LangSmith 跟踪 中,我们可以看到各个 LLM 调用,按其各自节点分组。
深入了解
自定义
- 如上所示,您可以自定义 LLM 和提示词以适应映射和归约阶段。
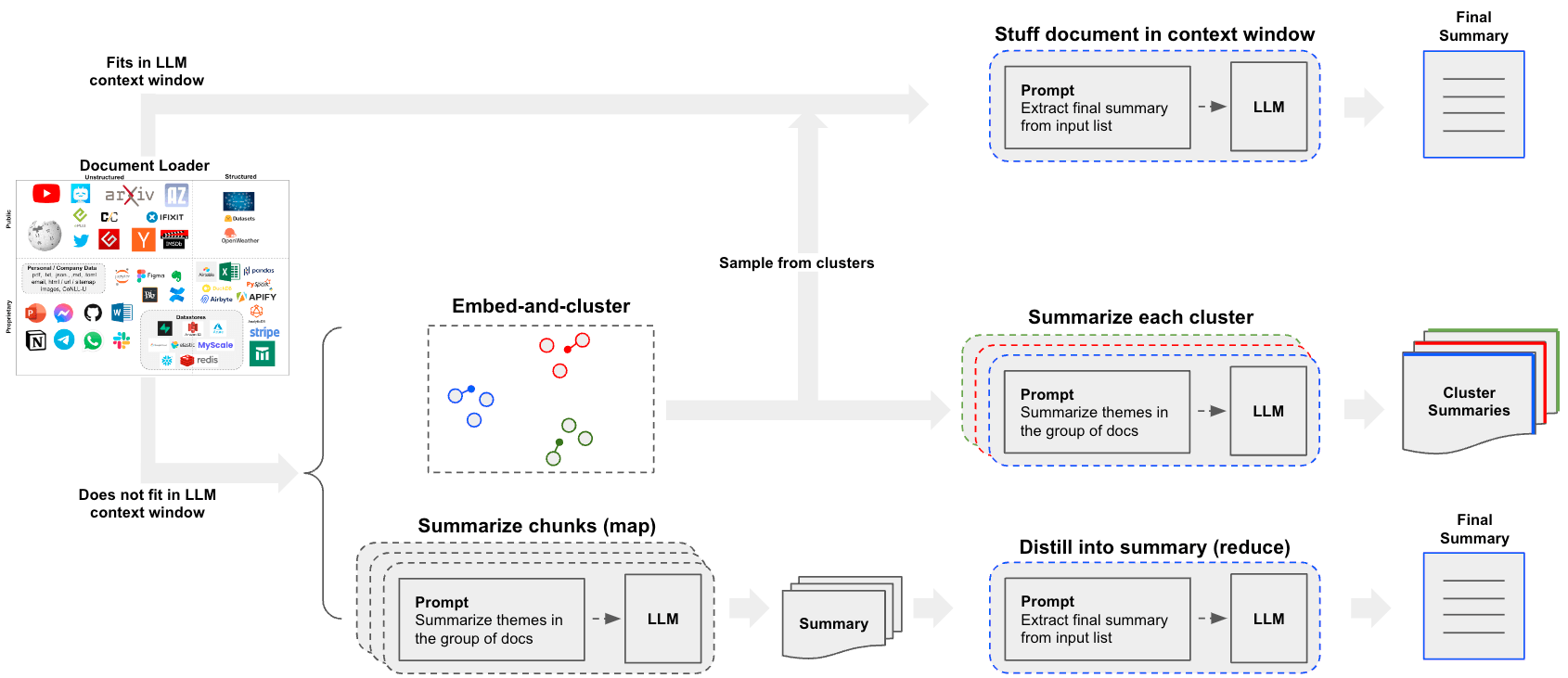
实际应用案例
- 请参阅 这篇博客文章 关于分析用户交互(关于 LangChain 文档的问题)的案例研究!
- 该博客文章及相关 仓库 还介绍了聚类作为一种总结手段。
- 这为超越
stuff或map-reduce方法打开了另一条值得考虑的路径。
下一步
我们鼓励您查看使用指南以获取更多详细信息:
以及其他概念。

